Nesse vídeo, apresento um projeto com um Roteador Mikrotik que transforma um veículo em um centro de conectividade WiFi e cabeado!
Redes
BGP – Mandatory Well-Known (Path Attributes)
O Protocolo BGP utiliza diversos parâmetros para escolha de melhor rota quando há diversos caminhos para o mesmo destino, esses parâmetros são chamados de Path Atributes.
Cada atualização do BGP consiste em uma ou mais sub-redes (prefixos) vinculadas aos seus atributos.
Os Path Atributes são classificados em Well-Known ( bem conhecido ) ou Optional (opcional). Alguns desses atributos são obrigatórios e outros opcionais com validade local na tabela de roteamento, local no AS, etc.
Os atributos Well-Known são classificados em Mandatory(obrigatório ) e Discretionary ( arbitrário).
No tópico de hoje citaremos os atributos Mandatory, Well-Known (bem conhecidos e obrigatórios).
Mandatory Well-Known
São 3 os atributos Mandatory Well-Known – Origin, AS-Path e Next-hop:
Origin: Relaciona a maneira que a rota foi aprendida pelo BGP. Se a rota foi declarada com o comando network ou via agregação de rotas ela será exibida com a letra “i”, para as rotas aprendidas via redistribuição é utilizado o caracter “?”. Há ainda a possibilidade da rota ser aprendida via o protocolo EGP,”e” mas atualmente o mesmo está em desuso.
AS-Path: Quando um prefixo é injetado no BGP e compartilhado entre os AS, inicialmente o AS-Path é atribuído como vazio, cada vez que a rota atravessa um AS(Sistema Autônomo) é adicionado pelos roteadores de Borda o numero do AS que ele pertence. É possível rastrear a sequencia de Sistemas Autônomos utilizando o atributo AS-Path.
Next-hop: Indica o endereço do próximo salto do Roteador que recebeu o prefixo. Geralmente o roteador que anuncia determinado prefixo repassa com o next-hop o seu próprio IP, exceto em sessões iBGP.
SHOW
O comando show ip bgp exibirá a saída da tabela BGP do Roteador com Cisco IOS:
Router>show ip bgp
BGP table version is 2709, local router ID is 172.16.1.1
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
S Stale
Origin codes: i - IGP, e - EGP, ? - incomplete
Network Next Hop Metric LocPrf Weight Path
Network Next Hop Metric LocPrf Weight Path
* i1172.31.1.0/29 0.0.0.0 0 100 32768 i
* i1172.16.10.0/24 0.0.0.0 0 100 32768 ?
* i1172.16.11.0/24 192.168.85.22 0 100 0 65510 65544 65516 65541 ?
*> 192.168.85.23 0 0 65510 65544 65516 65541 ?
* i1172.16.12.0/22 192.168.85.22 0 100 0 65510 65544 65516 65541 ?
*> 192.168.85.23 0 0 65510 65544 65516 65541 ?
[saída omitida]
! A rede 172.31.1.0/29 está diretamente conectada no Roteador e inserida processo via comando Network ! Já a rede 172.16.10.0/24 foi inserida na tabela BGP via processo de redistribuição
Peering BGP
O comando show ip bgp summary exibe os “peerings” BGP:
Router>show ip bgp summary BGP router identifier 172.16.1.1, local AS number 65500 BGP table version is 2709, main routing table version 2709 258 network entries using 29154 bytes of memory 510 path entries using 24480 bytes of memory 6725/10 BGP path/bestpath attribute entries using 672500 bytes of memory 2 BGP rrinfo entries using 48 bytes of memory 856 BGP AS-PATH entries using 32108 bytes of memory 270 BGP community entries using 7536 bytes of memory 12 BGP extended community entries using 304 bytes of memory 197 BGP route-map cache entries using 6304 bytes of memory 0 BGP filter-list cache entries using 0 bytes of memory BGP using 772434 total bytes of memory BGP activity 449536/418807 prefixes, 1538082/1477309 paths, scan interval 60 secs Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd 192.168.85.22 4 65510 962698 517851 2701 0 0 1w2d 24 192.168.85.23 4 65510 517865 517853 2701 0 0 1w2d 25 Router>
Até logo!
Netflow
por Woshington Silva
O NetFlow é uma tecnologia desenvolvida pela Cisco e já vem integrada ao IOS de seus equipamentos permitindo a coleta de informações e estatísticas do tráfego de uma rede.
Ao invés de apenas contar os pacotes, o NetFlow considera esses pacotes como parte de um fluxo, monitorando o início, meio e fim. Podemos definir um fluxo como uma sequencia unidirecional de pacotes que possuem características comuns entre a origem e o destino.
Para que os pacotes possam fazer parte do mesmo fluxo, as características abaixo devem ser apresentadas:
- Mesmo Endereço de Origem;
- Mesmo Endereço de destino;
- Mesma Porta lógica de origem;
- Mesma Porta lógica de destino;
- Mesmo Protocolo de camada 3;
- Mesmo Tipo de serviço (ToS);
- Mesma interface (independente de ser física ou lógica);
Um fluxo é extinguindo quando:
- Sua inatividade supera 15 segundos;
- Sua duração ultrapassa 30 minutos;
- Uma conexão TCP é encerrada ;
- A tabela de fluxos está cheia ou usuário redefine configurações de fluxo;
Obs: Quando um pacote é recebido e o mesmo não pertencer a nenhum fluxo existente, ocorrerá a criação de um novo fluxo.
Quando o fluxo é identificado, as informações são armazenadas na tabela cache NetFlow. Podemos também transferi-las para um coletor que exibira as informações em formas de relatórios e gráficos. Porém essas informações serão enviadas ao coletor após o término do fluxo.
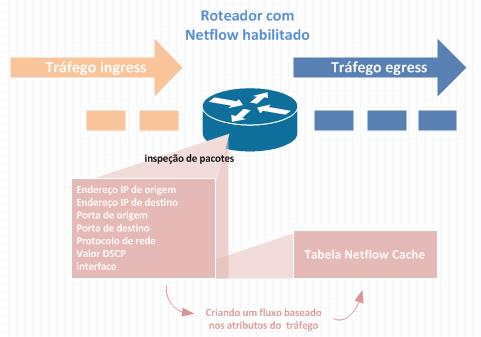
O NetFlow é inteiramente transparente para os outros dispositivos da rede, não exige nenhuma configuração nos elementos que serão monitorados. Sua única exigência é que seja habilitada na interface do equipamento (Roteador).
Abaixo veremos uma configuração básica do Netflow.
Configurando o Netflow no router: Router(config)# ip flow-export destination a.b.c.d 9997 !Endereço IP do servidor e porta UDP Router(config)# ip flow-export version 9 Router(config)# ip flow-export source Ethernet 0/1
obs: a versão do netflow e a porta devem ser a mesma do coletor, outro ponto importante é o que o ip cef esteja habiltado.
Configurando as interfaces: Router(config)# interface Ethernet 0/0 Router(config-if)# ip route-cache flow Router(config-if)# ip flow ingress
Existem duas formas de verificarmos os dados coletados: a primeira, via CLI e a segunda via o coletor, ressaltando mais uma vez que os dados só serão coletados após o término do fluxo. Caso haja o desejo de analisar o tráfego em tempo real, o ideal é usarmos os comandos via CLI.
Um dos comandos via CLI em que possamos verificar os dados é o:
Router# show ip cache flow
Onde obtemos informações como distribuição do tamanho dos pacotes, número de fluxos ativos, protocolos utilizados, interface de origem e destino, endereço IP de origem e destino, porta de origem e destino e tamanho dos pacotes.
Particularmente tive um experiência muito satisfatória ao usar o NetFlow, na empresa em que trabalho recebemos a solicitação para a abertura de um chamado, onde o cliente informava que o link de uma determinada localidade estava com alta utilização e gostaria de receber um relatório com a origem desse tráfego.
Após contato com o cliente, identificamos que o mesmo não possuía um coletor para construção de gráficos e relatórios baseados em Netflow, a única coisa que nos restava era usar os recursos que a CLI podia nos oferecer. Então decidimos configurar o roteador para que exibisse os 10 maiores fluxo por pacote.
Para que isso fosse possível utilizamos os seguintes comandos na CLI:
Router(config)# ip flow-top-talkers Router(config-flow-top-talkers)# top 10 Router(config-flow-top-talkers)# sort-by packets
Para visualizar os top 10 o comando é show ip flow top-talkers.
Em resumo, com o NetFlow podemos obter benefícios como:
- Monitoramento da banda ;
- Análise de tráfego;
- Análise da rede;
- Gerência de segurança;
- Monitoramento de aplicativos;
- Rastreamento da migração de aplicativos;
- Validação de QoS;
- Planejamento de capacidade;
- Identificação de worms e malwares

Ou seja, podemos considerar o NetFlow como uma importante ferramenta que nos possibilita compreender, melhorar e identificar possíveis problemas que estão acorrendo na rede.
Referências
Distância Administrativa
por Woshington Silva
Os roteadores utilizam a distância administrativa para escolher o melhor caminho quando aprendem mais de uma rota para o mesmo destino através de protocolos distintos. A confiabilidade de um protocolo de roteamento é definida através da distância administrativa.
Quanto menor o valor da distância administrativa mais confiável o protocolo. Esses valores variam de 0 à 255, onde 0 é mais confiável e 255 é menos confiável
Exemplo:
Em um roteador temos duas rotas aprendidas por protocolos distintos para uma determinada rede, a primeira rota foi descoberta pelo protocolo de roteamento RIP e a segunda pelo protocolo de roteamento OSPF. Baseando-se na tabela abaixo, qual caminho o roteador irá escolher?

*Valores padrão de distância administrativa dos protocolos suportados pela Cisco
Ao verificarmos a tabela acima vimos que a rota onde apresenta o protocolo OSPF será escolhida como melhor caminho e assim inserida na tabela de roteamento, já que o valor 110 do protocolo OSPF está mais próximo de 0 do que o valor 120 do protocolo RIP. Portanto o protocolo OSPF é mais confiável do que o protocolo RIP.
Porém se por algum motivo quiséssemos alterar o valor padrão da distancia administrativa, isso é possível através do comando “distance”, conforme veremos abaixo:
Router(config)#router rip Router(config-router)# distance 80 Router(config-router)# end
Se aplicarmos essa configuração no exemplo acima o roteador adicionará na tabela de roteamento a rota do protocolo RIP ao invés da rota do protocolo OSPF, já que agora o valor da distância administrativa do RIP passará a ser de 80, portanto menor que 110 da distância administrativa do OSPF.
Obs: Caso haja uma alteração no valor padrão para 255, o roteador não incluirá a rota na tabela de roteamento, ele irá entender que a rota é totalmente não-confiável.
E se a duas rotas fossem descobertas pelo mesmo protocolo de roteamento?
Quando isso acontece, o roteador irá escolher a rota que tiver a melhor métrica e assim inseri-la na tabela de roteamento.
Uma informação importante é que a distância administrativa tem um significado local, sendo assim, ela não é anunciada nas atualizações de roteamento, se você alterar o valor padrão só o roteador onde ocorreu a mudança sentirá o efeito.
Por fim…
Podemos verificar a distância administrativa com aos seguintes comandos show ip route e show ip protocols, conforme veremos nas imagens abaixo:

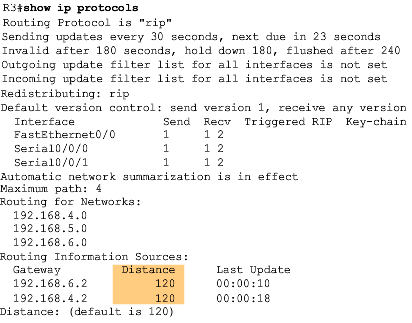
Até o próximo artigo!
MPLS (Multi Protocol Label Switching) – parte 2
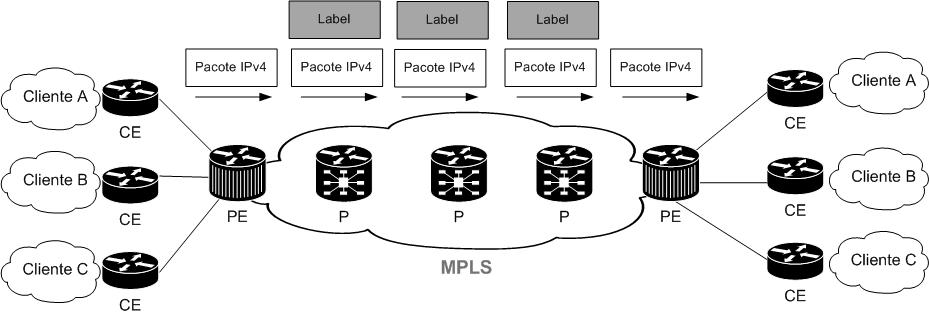
Como iniciado no primeiro post, em uma rede com arquitetura MPLS cada roteador da topologia possui uma designação que define a sua posição e atribuição na topologia:
- CE (Customer Edge Router) – possui a função de prover conectividade para a rede MPLS e é situado na “borda do cliente”. Não encaminha e nem troca labels.
- PE (Provider Edge Router) – é responsável pela conexão entre uma rede IP (rede do cliente) e a rede MPLS (rede da Operadora/Provider)
- P (Provider Edge Router) – é responsável pelo encaminhamento de pacotes baseando-se nos labels.
Label Switch Router
Diversas documentações também atribuem um nome mais genérico para roteadores que tratam o recebimento e encaminhamento de pacotes MPLS, chamados de Label Switch Routers(LSR). Na topologia, os LSR podem ser chamados de:
- Ingress LSRs – responsáveis por receber um pacote não “rotulado” e inserir o Label
- Egress LSRs – responsáveis por receber um pacote “rotulado” e remover o Label
- Intermediate LSRs – responsáveis por inserir, encaminhar e trocar Labels.
Os Roteadores LSRs são responsáveis por três operações principais para encaminhamento de pacotes e/ou labels: POP (remover o label), PUSH (inserir o label) ou SWAP (trocar o label).
A seqüência de Roteadores LSRs que são responsáveis pela comutação de um pacote com label em uma rede MPLS, é chamada de LSP (Label Switched Path).
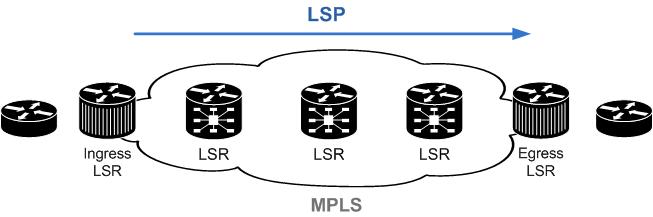
O LSP é definido como o caminho por onde os pacotes irão passar numa rede MPLS. No momento em que um pacote entra numa rede MPLS, este é associado a uma classe de equivalência (FEC) e assim é criado um LSP relacionado a esta FEC.
Como a criação de uma LSP só ocorre na entrada de uma rede MPLS, os LSR ( Label Switch Router) da nuvem só terão o trabalho de fazer as trocas dos rótulos (swap), encaminhando assim o pacote de acordo com o LSP determinado anteriormente, não havendo mais a necessidade de fazer o roteamento dos pacotes (somente a comutação via Label).
Protocolos de distribuição de Labels
Atualmente são utilizados 2 principais protocolos para distribuição de Rótulos em uma rede MPLS, (daremos um foco especial no LDP):
- Label Distribution Protocol (LDP)
- Resource Reservation Protocol – Traffic Engineering (RSVP-TE)
O vinculo de Rótulos é a associação de um label a um prefixo (rota). O LDP trabalha em conjunto com um IGP (OSPF, IS-IS, etc) para anunciar os vínculos de labels (binding) para as rotas, como por exemplo, em um backbone. Conforme desenho abaixo:
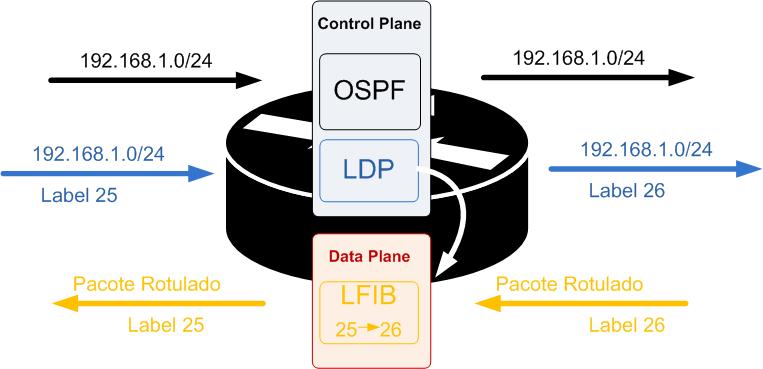
Resumidamente, é atribuído um valor de label para cada prefixo. No exemplo abaixo segue o exemplo da configuração do LDP em um Roteador P com o processo OSPF em um roteador com IOS Cisco.

Exemplo de Configuração do Roteador P
ip cef
mpls ip
mpls ldp router-id loopback 0
!
int loo 0
ip add 10.2.2.2 255.255.255.255
!
interface FastEthernet0/0
ip address 10.1.1.5 255.255.255.252
mpls label protocol ldp
mpls ip
!
interface FastEthernet0/1
ip address 10.1.1.1 255.255.255.252
mpls label protocol ldp
mpls ip
!
!
router ospf 1
log-adjacency-changes
network 10.1.1.0 0.0.0.3 area 0
network 10.1.1.4 0.0.0.3 area 0
network 10.2.2.2 0.0.0.0 area 0
!
----------------------------------------------
R2#show mpls forwarding-table
Local Outgoing Prefix Bytes tag Outgoing Next Hop
tag tag or VC or Tunnel Id switched interface
23 Pop tag 10.1.1.0/30 636 Fa0/0 point2point
24 Pop tag 10.1.1.4/30 641 Fa0/1 point2point
25 26 192.168.1.0/24 234 Fa0/0 point2point
26 30 192.168.1.0/24 143 Fa0/1 point2point
27 28 192.168.2.0/30 143 Fa0/1 point2point
-
R2#show mpls ldp neighbor
Peer LDP Ident: 10.1.1.2:0; Local LDP Ident 10.1.1.5:0
TCP connection: 10.1.1.2.646 - 10.1.1.1.11012
State: Oper; Msgs sent/rcvd: 21/21; Downstream
Up time: 00:10:29
LDP discovery sources:
FastEthernet0/0, Src IP addr: 10.1.1.2
Addresses bound to peer LDP Ident:
10.1.1.2
Peer LDP Ident: 10.1.1.6:0; Local LDP Ident 10.1.1.5:0
TCP connection: 10.1.1.6.11000 - 10.1.1.5.646
State: Oper; Msgs sent/rcvd: 28/31; Downstream
Up time: 00:16:00
LDP discovery sources:
FastEthernet0/1, Src IP addr: 10.1.1.6
Addresses bound to peer LDP Ident:
10.1.1.6 192.168.1.0 192.168.2.0
Referências
http://www.gta.ufrj.br/grad/04_2/MPLS/conceitos.htm
http://blog.ccna.com.br/2008/09/12/multi-protocol-label-switching-mpls-parte-3/
BGP Communities
O protocolo BGP possui a versatilidade de agregar redes e atributos; anunciando e modificando cada prefixo de maneira individual. Um desses atributos, o Community permite “taguear” o anuncio de cada rede individualmente de acordo com o negócio, políticas de roteamento ou para fins de troubleshooting.
De forma básica o uso de community (ou “comunidade BGP” em português) pode ser usado como uma flag para marcar um determinado grupo de rotas.
Provedores de Serviço utilizam essas marcações para aplicar políticas de roteamento específicas em suas redes, por exemplo alterando o Local Preference, MED ou Weight.
O atributo community é opcional e transitivo (optional transitive) e de tamanho variável, isto é, implementações BGP não necessitam reconhecer o atributo e fica ao critério do administrador de rede alterar ou reencaminhar para outros pares . O atributo consiste em um número de 32 bits que específica uma community. Sendo que sua representação é feita AA:NN onde o AA é o Autonomous System (AS) e o NN é o número da community.
Um prefixo pode participar de mais de uma community e os roteadores BGP podem tomar uma ação em relação à um prefixo baseado em uma, algumas ou todas as communities associadas ao prefixo.
O comando utilizado para configurar uma community em um Roteador Cisco (baseado no IOS) é via set community dentro de um route-map:
R1(config-route-map)#set community ? <1-4294967295> community number aa:nn community number in aa:nn format additive Add to the existing community internet Internet (well-known community) local-AS Do not send outside local AS (well-known community) no-advertise Do not advertise to any peer (well-known community) no-export Do not export to next AS (well-known community) none No community attribute
O comando “set community” apaga a comunidade existente vinculada a um prefixo substituindo-o pela nova community, a menos que seja especificado o comando additive após o valor da community.
R1(config-route-map)#set community 65535:1 additive
A community pode ser aplicada em um ou mais prefixos com a utilização de route-maps nos seguintes itens do processo BGP:
- No peering BGP de in/out
- Redistribuição
- Comando network
Três communities são definidas e reservadas na RFC 1997 para implementações BGP: NO-EXPORT (0xFFFFFF01 ), NO-ADVERTISE (0xFFFFFF02 ), and NO-ADVERTISE-SUBCONFED (0xFFFFFF03 ). Adicionalmente, NO-PEER (0xFFFFFF04 ) tem sido proposta em um draft para Internet [3].
NO-EXPORT é geralmente utilizado dentro de um AS para instruir os roteadores para não exportar o prefixo para vizinhos eBGP.
NO-ADVERTISE instrui um roteador BGP para não encaminhar o prefixo “tagueado” para qualquer vizinhos, seja iBGP ou eBGP.
NO-ADVERTISE-SUBCONFED é utilizado para prevenir um prefixo de ser anunciado para outros membros dentro da confederação.
NO-PEER é usado em situações onde é necessário o controle de engenharia de tráfego ao longo de um prefixo “mais específico”, restringindo a sua propagação apenas aos prestadores de trânsito e não seus pares. Ou seja, o prefixo é anunciado de AS para AS, desde que haja uma relação de trânsito / cliente, ao contrário do NO-EXPORT, que restringe a propagação do prefixo somente ao AS adjacente. Atualmente tal comunidade não é reconhecido pela maioria dos fabricantes e requer uma implementação manual.
Durante processos complexos de redistribuição de IGPs no BGP, o uso de community pode ser usado para detectar o protocolo de origem (por exemplo, uma community para IS-IS outra definida para OSPF, etc).
Community List
A Community-list é como uma ACL, só que para communities. Essas listas são adicionadas com o comando “ip community-list ” onde o valor é representado por “AA:NN” ou por caracteres especiais como, por exemplo, “*” que representa tudo.
Exemplo de configuração
No exemplo abaixo iremos anunciar 3 prefixos do ASN 65524, dois serão marcados com community e um sem community. No ASN 65525 iremos atribuir um valor de local preference para cada prefixo de acordo com a comunidade atribuída.
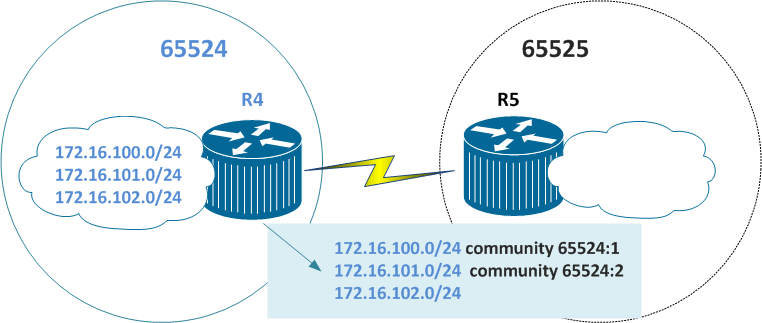
Roteador R4 ! ip bgp-community new-format ! Exibe o valor da community de 32 bits dividido em 2 de 16 separados por ":" ! ! Configurando as route-maps para atribuir o valor de community route-map SET_COMM_B permit 10 set community 65524:2 ! route-map SET_COMM_A permit 10 set community 65524:1 ! router bgp 65524 no synchronization bgp log-neighbor-changes network 172.16.100.0 mask 255.255.255.0 route-map SET_COMM_A network 172.16.101.0 mask 255.255.255.0 route-map SET_COMM_B network 172.16.102.0 mask 255.255.255.0 ! Anunciando as redes no processo BGP de acordo com as communities atribuídas neighbor 192.168.45.5 remote-as 65525 neighbor 192.168.45.5 send-community ! Permitindo o envio de community para o peer BGP no auto-summary ! ip classless ip route 172.16.100.0 255.255.255.0 Null0 ip route 172.16.101.0 255.255.255.0 Null0 ip route 172.16.102.0 255.255.255.0 Null0 ! end
Roteador R5
!
ip bgp-community new-format
! Exibe o valor da community de 32 bits dividido em 2 de 16 separados por ":"
!
! Community-list para filtro de valores de Communities
ip community-list standard LOCAL_PREF_150 permit 65524:1
ip community-list standard LOCAL_PREF_200 permit 65524:2
!
!
route-map SET_LOCAL_PREF permit 10
match community LOCAL_PREF_150
set local-preference 150
! Atribuindo o local preference aos prefixos da community-list
!
route-map SET_LOCAL_PREF permit 20
match community LOCAL_PREF_200
set local-preference 200
! Atribuindo o local preference aos prefixos da community-list
!
route-map SET_LOCAL_PREF permit 30
!
router bgp 65525
neighbor 192.168.45.4 remote-as 65524
neighbor 192.168.45.4 send-community
neighbor 192.168.45.4 route-map SET_LOCAL_PREF in
! Atribuíndo os route-maps configurados no peering BGP
no auto-summary
!
ip classless
!
end
!
! Verificando o valor de Local Preference atribuído a cada prefixo
R5#show ip bgp
BGP table version is 4, local router ID is 192.168.45.5
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure
Origin codes: i - IGP, e - EGP, ? – incomplete
Network Next Hop Metric LocPrf Weight Path
*> 172.16.100.0/24 192.168.45.4 0 150 0 65524 i
*> 172.16.101.0/24 192.168.45.4 0 200 0 65524 i
*> 172.16.102.0/24 192.168.45.4 0 0 65524 i
!
! Verificando o valor de community atribuído ao prefixo
R5#show ip bgp 172.16.100.0
BGP routing table entry for 172.16.100.0/24, version 2
Paths: (1 available, best #1)
Not advertised to any peer
65524
192.168.45.4 from 192.168.45.4 (192.168.45.4)
Origin IGP, metric 0, localpref 150, valid, external, best
Community: 65524:1
Até logo!!!
Referências
http://babarata.blogspot.com.br/2010/05/bgp-atributo-community.html
http://www.cisco.com/web/about/ac123/ac147/archived_issues/ipj_6-2/bgp_communities.html
IKE Fase 1: Resumo
Quando você está tentando fazer a uma conexão segura entre 2 hosts através da Internet, um caminho seguro deverá ser estabelecido, como por exemplo, por uma conexão VPN IPSec. Além dos mecanismos de autenticação e validação da informação a VPN IPSec necessita de um mecanismo eficiente de gestão de chaves.
O processo de gestão de chaves diz respeito à criação, eliminação e alteração das chaves. A implementação de uma solução VPN IPSec utliza-se de um processo de criptografia que envolve uma periódica troca de chaves, embora o IPSec não integre um mecanismo de gestão de chaves, o IETF definiu como norma de gestão o protocolo híbrido ISAKMP/Oakley também denominado IKE, Internet Key Exchange para autenticar os dispositivos e gerar as chaves criptografadas. O protocolo IKE utiliza o termo security association (SA), que é um acordo entre os equipamentos pares para troca de tráfego IPSec utilizando os requerimentos necessários para estabelecer as proteções aplicadas em uma conexão.
No estabelecimento de uma comunicação segura, passa-se pelas seguintes fases IKE:
Fase 1: Ocorre num meio inseguro. Tem o objetivo de estabelecer um canal seguro que irá proteger as trocas da Fase 2. É executada uma vez para várias fases 2;
Fase 2: Ocorre no canal seguro criado na fase 1. As suas negociações têm o objetivo de estabelecer as associações de segurança que irão proteger a comunicação.
Após estas duas fases, encontra-se estabelecido um canal seguro através do qual ocorre comunicação segura. Nesse post abordaremos apenas a Fase 1.
IKE Fase 1
A principal finalidade dessa primeira troca é permitir que os equipamentos finais consigam definir os parâmetros SA para estabelecer um canal seguro para futuramente estabelecer uma conexão IPSec. Tal canal é chamado IKE SA. Esse canal tem a função de criar criptografia e autenticação bidirecional para as outras trocas IKE e passagem de pacotes IPSec.
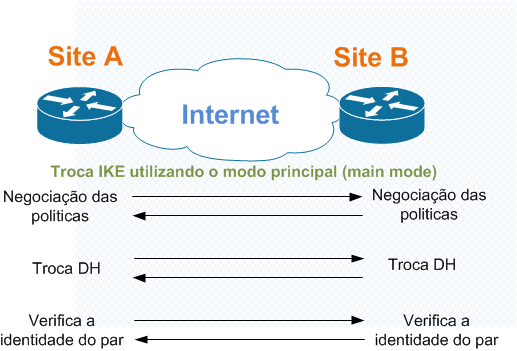
O IKE SA pode ser realizado de duas formas:
- Modo Principal (Main Mode): negocia a criação da conexão através da troca de três pares de mensagem.
- A primeira troca de mensagens é relativa as formas de criptografia, autenticação (escolha dos algoritmos) e criação de chaves assimétricas.
- A segunda troca de mensagens utiliza o algoritmo Diffie-Hellman para trocas das chaves criadas, da assinatura digital ou da chave pública, de acordo com os parâmetros definidos.
- O terceiro par de mensagens verifica a identidade do outro lado. O valor de identidade é o endereço IP do par IPSec na forma criptografada. A principal função do main mode é combinar IKE SA (security association) entre os pares para fornecer uma conexão protegidas para posteriores trocas ISAKMP entre os peers IKE. O IKE SA especifica valores para a troca IKE: o método de autenticação usado, a criptografia, os algoritmos de hash, o grupo Diffie-Hellman (DH) utilizado, a vida útil do IKE SA em segundos ou quilobytes, e os valores de chaves secretas compartilhadas para os algoritmos de criptografia. O IKE SA em cada par é bi-direcional.
- Modo Agressivo(Agressive Mode): é uma alternativa mais rápida ao modo principal, já que negocia a criação IKE SA através de três mensagens, ao invés de três pares de mensagens. A primeira mensagem de um dos extremos manda os parâmetros de segurança, juntamente com sua porção da chave criada por Diffie-Hellman e sua identidade. O outro extremo envia sua parte da chave, parâmetros de segurança e sua autenticação (geralmente por assinatura digital). Na última mensagem o primeiro extremo envia sua autenticação ao outro. Com essas três mensagens a conexão IKE SA está criada. Se ganha em velocidade, mas perde-se em segurança, por exemplo, as chaves podem ser interceptadas e forjadas.
No cenário abaixo, utilizando o Cisco IOS como exemplo, com o estabelecimento de uma conexão segura entre roteadores de uma empresa para uma VPN IPsec, em vez de negociarmos cada protocolo para criptografia, autenticação, etc , individualmente; podemos agrupar os protocolos em conjunto de politicas IKE (IKE policy).
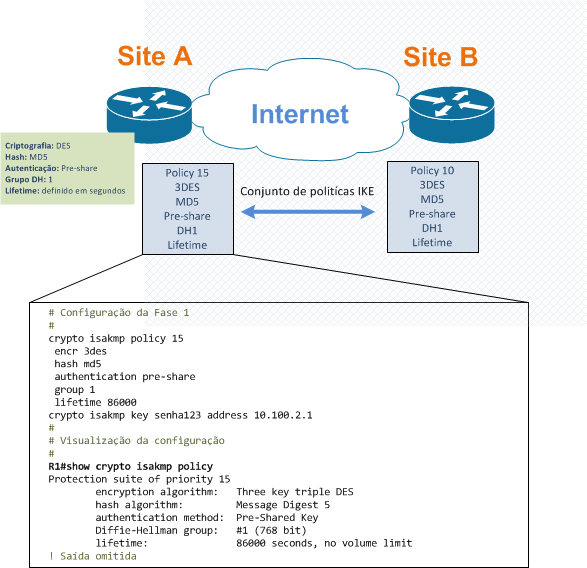
O comando crypto isakmp policy define o IKE Fase 1, com os parâmetros utilizados durante a negociação. A sintaxe do comando crypto isakmp policy “priority” define a prioridade da policy. Caso os valores de criptografia, hash, DH e lifetime não sejam configurados, serão escolhidos os valores default (des, sha, rsa-sig, 1 e 86400 respectivamente).
Para configurar a pre-shared key (PSK) utilize a sintaxe:
crypto isakmp key “tipo de cifragem da senha na configuração” senha hostname/ address endereço.
Nos próximos posts daremos continuidade no script para a Fase 2 e modos IPSec.
Referência
http://www.gta.ufrj.br/grad/08_1/vpn/ipsecelementos.html#_Toc200023677
http://civil.fe.up.pt/acruz/Mi99/asr/IPSec.htm
Implementing Cisco IOS Network Security , Cisco press – Catherine Paquet
Network Security Technologies and Solutions, Cisco press – Yusuf Bhaiji
Unicast RPF (uRPF)
A feature uRPF compara o endereço IP de origem do cabeçalho IP com a tabela de rotas, com o objetivo de descartar pacotes que não possuem uma referência de rotas em determinada interface. Em resumo, o roteador só encaminhará o pacote, se o endereço IP de origem inserido no cabeçalho for acessível por aquela interface de entrada.
Lembrando que por padrão, no encaminhamento de pacotes, o roteador irá validar apenas o endereço de destino de um pacote IP.
O uRPF possui 2 modos distintos (strict e loose) que podem potencialmente ajudar a reduzir ataques com endereços IP falsificados.
Em um exemplo simples, é como se um roteador com uma interface com o endereço de LAN 192.168.1.0/24 receber um pacote com o endereço de origem 172.16.1.20. Esse endereço não faz parte da rede local.
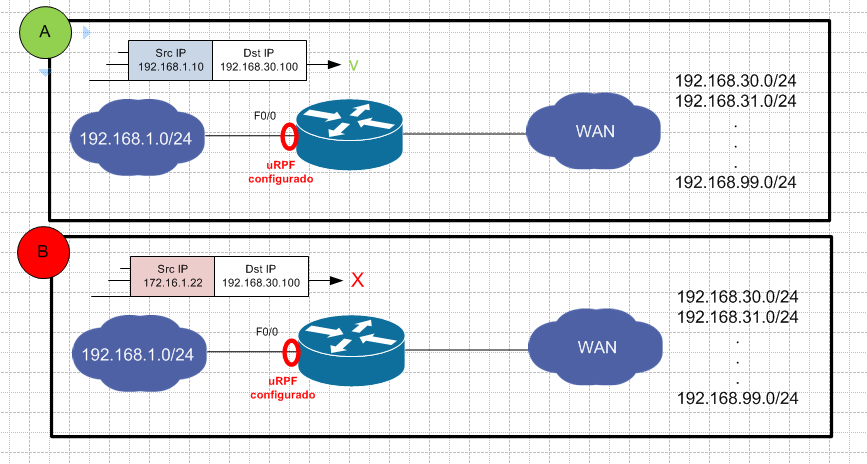
Unicast RPF Strict Mode
O uRPF strict mode permitirá apenas os pacotes acessíveis por aquela interface.
No caso de rotas com custos iguais, o tráfego também será encaminhado.
O roteador irá validar os pacotes que estão entrando no roteador e validará com a FIB. Se o pacote é recebido pela interface e tem rota para o endereço de origem do cabeçalho (para aquela interface), o pacote será recebido e encaminhado.
O comando a ser aplicado em uma interface é “ip verify unicast source reachable-via rx”. No caso de roteamento assimétrico, o tráfego será descartado.
R1(config-if)#ip verify unicast source reachable-via rx
Validando os pacotes descartados
R1 # show ip int fa0/0 | i ^ [1-9]+ verification drops
8 verification drops
R1# show ip traffic | i unicast
0 no route, 8 unicast RPF, 0 forced drop
Unicast RPF Loose mode
O uRPF configurado como loose mode, bloqueará pacotes que não possuem a rede de origem na tabela de roteamento. Por exemplo, caso haja duas interfaces com rotas diferentes para a mesma rede e o pacote vir por uma porta que não é a rota preferida pelo roteador, o mesmo roteará o pacote.
O uRPF loose mode é bastante útil para roteadores que aprendem suas rotas dinamicamente via BGP, descartando endereços privados,como da RFC 1918.
O comando a ser aplicado em uma interface é ‘ip verify unicast source reachable-via any‘. No caso de roteamento assimétrico o tráfego será encaminhado.
R1(config-if)#ip verify unicast source reachable-via any
Rota default
Caso o endereço seja apenas conhecido via rota default, o uRPF continuará bloqueando os endereços. Para permitir os endereços a partir da rota default use o comando “ip verify unicast source reachable-via rx allow-default”
Referências
http://slaptijack.com/networking/ciscos-new-ip-verify-unicast-source-reachable-via/
http://networkengineering.stackexchange.com/questions/3133/unicast-rpf-on-the-edge
http://www.cisco.com/c/en/us/td/docs/ios/12_2/security/configuration/guide/fsecur_c/scfrpf.html
Obs: os testes foram efetuados em um roteador Cisco 7200 com IOS (C7200-ADVSECURITYK9-M), Version 12.4(24)T1
Roteamento entre VRFs com MP-BGP
A utilização de VRFs (Virtual Routing and Forwarding) em Roteadores permite a criação de tabelas de roteamento virtuais que trabalham de forma independente da tabela de roteamento “normal”, protegendo os processos de roteamento de cada cliente de forma individual.
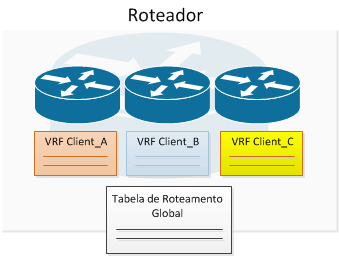
Empresas que prestam serviços de gerenciamento de rede ou monitoração, empresas que vendem serviços em Data Center e provedores de serviço utilizam largamente VRFs, otimizando assim a administração e o retorno financeiro no total do custo de um projeto.
A configuração de VRFs é bem simples. Já o Roteamento entre VRFs ocorre quando há a necessidade de comunicarmos diferentes tabelas de roteamento que estão segregadas por VRF, para compartilharem alguns ou todos os prefixos. Há diversas formas de configurarmos o roteamento entre VRFs, como por exemplo com a utilização de um cabo virado para o próprio roteador com as portas em diferente VRFs [apontando assim uma rota para nexthop da proxima VRF; ou com algum IGP] e também com a utilização de um outro roteador, etc; nesse post explicaremos o roteamento interVRF com o processo MPBGP que é a maneira mais escalável… preparados? Então vamos lá…
Habilitando o import e export das VRFs
Ao configurarmos o processo de roteamento entre VRFs em um mesmo roteador , dois valores de extrema importancia devem ser configurados na VRF: o RD (route distinguisher) e o RT (route target)
RD
Como explicado anteriormente, as VRFs permitem a reutilização de endereços IP em diferentes tabelas de roteamento. Por exemplo, suponha que você tenha que conectar a três diferentes clientes , os quais estão usando 192.168.1.0/24 em sua rede local. Podemos designar a cada cliente a sua própria VRF de modo que as redes sobrepostas são mantidas isoladas em suas VRFs .
O RD funciona mantendo o controle de quais rotas 192.168.1.0/24 pertencem a cada cliente como um diferenciador de rota (RD) para cada VRF. O route distinguisher é um número único adiciondo para cada rota dentro de uma VRF para identificá-lo como pertencente a essa VRF ou cliente particular. O valor do RD é carregado juntamente com uma rota através do processo MP- BGP quando o roteador troca rotas VPN com outros Roteadores PE.
O valor RD é de 64 bits e é sugerido a configuração do valor do RD como ASN::nn ou endereçoIP:nn. Mas apesar das sugestões, o valor é apenas representativo.
R1(config-vrf)#rd ? ASN:nn or IP-address:nn VPN Route Distinguisher ! Configurando a VRF para os clientes A B e C ip vrf Cliente_A rd 65000:1 ! ip vrf Cliente_B rd 65000:2 ! ip vrf Cliente_C rd 65000:3
Quando rotas VPN são anunciados entre os roteadores PE via MP-BGP, o RD é incluído como parte da rota, juntamente com o prefixo IP. Por exemplo, uma via para 192.0.2.0/24 na VRF Cliente_B é anunciado como 65000:2:192.0.1.0 / 24.
RT
Considerando que o valor do RD é utilizado para manter a exclusividade entre rotas idênticas em diferentes VRFs, o RT (route target)é utilizado para compartilhar rotas entre eles. Podemos aplicar o RT para uma VRF com o objetivo de controlar a importação e exportação de rotas entre ela e outras VRFs.
O route target assume a forma de uma comunidade BGP estendida com uma estrutura semelhante à de um RD (que é, provavelmente, porque os dois são tão facilmente confundidos).
Segue abaixo um exemplo de configuração, onde o Cliente_A fará o roteamento entre VRFs com o Cliente_B, já o Cliente_C continuará com a sua VRF isolada dos outros clientes.
! ip vrf Cliente_A rd 65000:1 route-target export 65000:1 route-target import 65000:1 route-target import 65000:2 ! ip vrf Cliente_B rd 65000:2 route-target export 65000:2 route-target import 65000:2 route-target import 65000:1 ! ip vrf Cliente_C rd 65000:3 route-target export 65000:3 route-target import 65000:3 !

Segue abaixo a configuração das interfaces de cada VRF , e o processo MP-BGP responsável por funcionar o import/export de prefixos das VRFs.
! interface Loopback0 ip address 192.168.1.1 255.255.255.0 ! interface Loopback1 ip vrf forwarding Cliente_A ip address 1.1.1.1 255.255.255.0 ! interface Loopback2 ip vrf forwarding Cliente_B ip address 2.2.2.2 255.255.255.0 ! interface Loopback3 ip vrf forwarding Cliente_C ip address 3.3.3.3 255.255.255.0 ! router bgp 65000 no synchronization bgp log-neighbor-changes no auto-summary ! address-family ipv4 vrf Cliente_A redistribute connected no synchronization exit-address-family ! address-family ipv4 vrf Cliente_B redistribute connected no synchronization exit-address-family ! address-family ipv4 vrf Cliente_C redistribute connected no synchronization exit-address-family !
Segue abaixo os outputs das rotas aprendidas para o roteamento entre VRFs e o teste de ICMP
R1#show ip route vrf Cliente_A
Gateway of last resort is not set
1.0.0.0/24 is subnetted, 1 subnets
C 1.1.1.0 is directly connected, Loopback1
2.0.0.0/24 is subnetted, 1 subnets
B 2.2.2.0 is directly connected, 00:08:22, Loopback2
R1#ping vrf Cliente_A 2.2.2.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 2.2.2.2, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/4 ms
Para dúvidas ou sugestões deixe um comentário.
Vídeo aulas: Switches Comware
Galera, compartilho com muito carinho o Treinamento Comware para Switches HP (não oficial) onde damos um overview das principais funcionalidades para os switches! São 8 aulas com bastante conteúdo.
