O protocolo OSPF permite a todos roteadores em uma área ter a visão completa da topologia. O protocolo possibilita assim a decisão do caminho mais curto baseado no custo que é atribuído a cada interface, com o algoritmo Dijkstra. O custo de uma rota é a soma dos custos de todas as interfaces de saída para um destino. Por padrão, os roteadores calculam o custo OSPF baseado na fórmula Cost =Reference bandwidth value / Link bandwidth.
Caso o valor da “largura de banda de referência” não seja configurado, os roteadores usarão o valor de 100Mb para cálculo. Por exemplo, se a interface for 10Mb, calcularemos 100Mb dividido por 10Mb, então o custo da interface será 10. Já os valores fracionados, serão arredondados para valor inteiro mais próximo e toda velocidade maior que 100Mb será atribuído o custo 1.
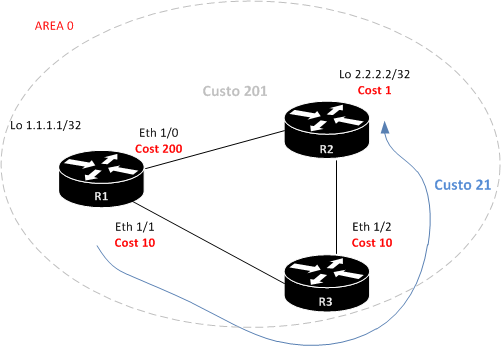
Veja no exemplo abaixo o custo que o R1 atribui as suas interfaces:
R1#show ip ospf interface ethernet 1/1
Ethernet1/1 is up, line protocol is up
Internet Address 192.168.13.1/24, Area 0
Process ID 1, Router ID 1.1.1.1,Network Type BROADCAST,Cost: 10
! saída omitida
R1#show ip ospf interface ethernet 1/0
Ethernet1/0 is up, line protocol is up
Internet Address 192.168.12.1/24, Area 0
Process ID 1, Router ID 1.1.1.1,Network Type BROADCAST,Cost: 10
! saída omitida e o custo atribuído para a Loopback é 1
R1#show ip ospf interface loo 1
Loopback1 is up, line protocol is up
Internet Address 1.1.1.1/24, Area 0
Process ID 1, Router ID 1.1.1.1, Network Type LOOPBACK, Cost: 1
O custo do Roteador R1 para a Loopback do Roteador R2 será 11.
R1#show ip route | inc 2.2.2.2
O 2.2.2.2 [110/11] via 192.168.12.2, 01:01:46, Ethernet1/0
Alterando o custo de uma interface …
R1#interface Ethernet1/0 ip ospf cost 200 ! Alterando o custo da interface para 200
R1#show ip route 2.2.2.2 Routing entry for 2.2.2.2/32 Known via "ospf 1", distance 110, metric 21, type intra área Last update from 192.168.13.3 on Ethernet1/1, 00:10:06 ago Routing Descriptor Blocks: * 192.168.13.3, from 2.2.2.2, 00:10:06 ago, via Ethernet1/1 Route metric is 21, traffic share count is 1
Caso seja necessário alterar a referência para largura de banda utilize o seguinte comando em um roteador Cisco IOS:
R1(config)# router ospf 100
R1(config-router)#auto-cost reference-bandwidth ?
The reference bandwidth in terms of Mbits per second
O “auto-cost reference-bandwidth 100″ é o default para 100Mb, onde 100Mb na topologia tem o custo = 1 . Assim, para ter links 1G com o custo = 1 , o “auto-cost…” deve ser configurado como 1000. Se a referência for links 10G , “auto-cost…” seria 10000 , para 100G, seria 100000 .
Obs: Lembre-se de sempre manter o “auto-cost reference-bandwidth” consistente em todos os roteadores para evitar comportamentos inesperados no roteamento.
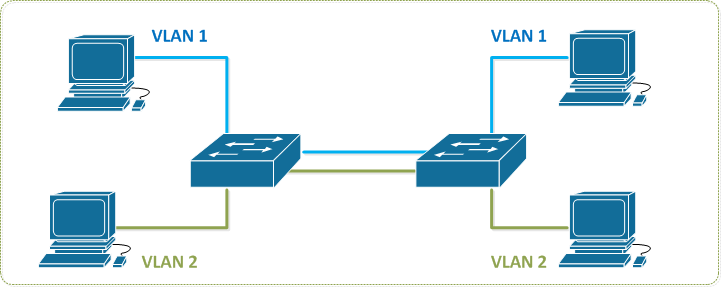
A utilização de VLAN (Virtual Local Area Network) permite que uma rede física seja dividida em várias redes lógicas dentro de um Switch. A partir da utilização de VLANs, uma estação não é capaz de comunicar-se com estações que não são pertencentes a mesma VLAN (para isto, é necessário a utilização de uma sub-rede por VLAN e que o tráfego passe primeiro por um roteador para chegar a outra rede [ou utilizando um Switch Multicamada para efetuar o Roteamento]).
Se não utilizássemos uma interface como Trunk e precisássemos passar o tráfego da VLAN para o outro Switch, seria necessário a passagem de um cabo de cada VLAN para o outro dispositivo, como no exemplo abaixo.
Como a maioria dos Switches possui entre 24 e 48 portas a solução ficaria inviável, inutilizando a maioria das portas para conexões entre os dispositivos.
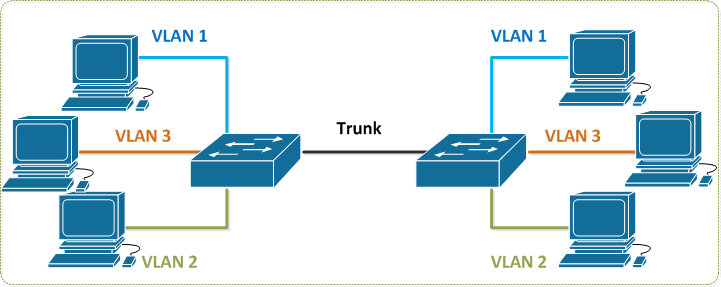
O protocolo IEEE 802.1q permite utilizarmos apenas um cabo na comunicação entre os Switches, marcando cada Frame (quadro) com o ID de cada VLAN.
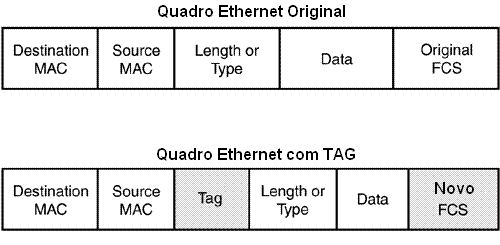
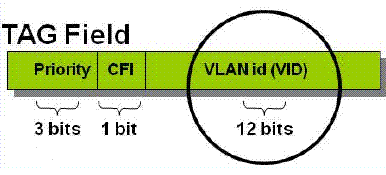
A marcação efetuada (chamada de TAG) adiciona aos quadros Ethernet 4 bytes no frame original e calculam um novo valor de checagem de erro para o campo FCS.
Dos valores contidos dentro do campo TAG o número da VLAN é adicionado ao campo VLAN id permitindo a identificação da VLAN entre os Switches.
Uma observação relevante é a utilização do campo Priority (também dentro da TAG) para função de QoS em camada 2 para Ethernet, chamado de 802.1p ou CoS (Class of Services), permitindo a diferenciação de classes de serviços por Switches sem a necessidade de leitura do campo IP.
Já a comunicação entre computadores no mesmo Switch que pertencem a mesma VLAN não são “tagueadas” (untagged). Muitas placas de rede para PC’s e impressoras não são compatíveis com o protocolo 802.1Q e ao receberem um frame tagged, não compreenderão o TAG de VLAN e descartarão a informação. Os Switches que recebem na sua interface Trunk um frame com TAG, irão remover o campo e entregar o quadro ao destino sem a marcação.
A regra é bem simples para a maioria dos casos (salvo exceções):
Para comunicação entre Switches, configure as interfaces como Trunk ( Tagged)
Para comunicação entre Switches e hosts, servidores, impressoras; configure as interfaces como Access (untagged) com o ID da VLAN
Configuração
Para a maioria dos Switches Cisco IOS, configure as portas como trunk da seguinte maneira (desde que as VLANs já tenham sido criadas no Switch ou aprendidas via VTP):
interface GigabitEthernet 1/0/x
! acesso a interface GigabitEthernet
port link-type trunk
! configuração da interface como trunk (frames encaminhados como tagged)
port trunk permit vlan all
! configuração da porta permitindo todas as VLANs no trunk
Um detalhe importante a ser percebido é sintaxe switchport trunk encapsulation dot1q . Apesar do protocolo 802.1q não encapsular o quadro Ethernet, a sintaxe Cisco solicita a configuração do protocolo via o comando . Suponho que a sintaxe deva ter surgido quando a Cisco apostava na utilização de interfaces Trunk utilizando o protocolo ISL que efetivamente encapsulava o quadro Ethernet.
Portas de acesso:
interface GigabitEthernet 1/0/x
! acesso a interface GigabitEthernet
port link-type access
! configuração da interface como acesso (frames encaminhados como untagged)
port access vlan 2
! configuração da porta na vlan 2
Obs: Por default os frames da VLAN 1 não são encaminhados com TAG dentro do Trunk.
O Cisco Meraki é um conjunto de soluções de rede gerenciadas pela internet que permite uma única fonte de gerenciamento sobre locais, infraestrutura e dispositivos. Componentes incluem uma solução completa de TI gerenciada por nuvem para atendimento as soluções de wireless, switching, segurança, gerenciamento de dispositivos móveis (MDM) e comunicações, integrando o hardware, software e a nuvem.
Há cinco maneiras pelas quais uma aplicação pode estender as funcionalidades da plataforma Meraki:
A Dashboard API, que fornece um serviço RESTful para provisionamento, gerenciamento e monitoramento de dispositivos.
Alertas de webhook, um serviço que permite atualizações em tempo real da saúde e configuração da rede.
A API de localização, um método HTTP POST configurado no Meraki Dashboard que fornece informações de localização do cliente (GPS, X/Y) com base no posicionamento do mapa do Meraki Access Point (AP) e na intensidade do sinal do cliente.
O External Captive Portal (EXCAP), que permite que uma organização crie modelos de engajamento personalizados para dispositivos que aproveitam seu ambiente WiFi.
MV Sense, que oferece chamadas de API REST e fluxo de dados em tempo real para aproveitamento das câmeras MV12
O ambiente “Meraki DevNet Always On Read Only Sandbox” fornece um ambiente de desenvolvimento para validar e testar o ‘Cisco Meraki Dashboard’, Dashboard API, integração do Captive Portal, MV Sense, Webhook Alerts e Location Scanning.
Todas as chamadas de API são muito bem documentadas usando a especificação OpenAPI (Swagger interface). Há ótimo trabalho disponibilizando tudo como um Documento Postman, um recurso muito útil no desenvolvimento de uma API.
O Postman é uma ferramenta de desenvolvimento de API baseada no modelo web/cliente, perfeita para simular chamadas e explorar como funcionam determinadas APIs. A plataforma da Meraki está atualmente na sua API versão 1.x .
Qual o uso das APIs? Existem muitos casos de uso para essas APIs, atendendo a requisitos de escalabilidade para os administradores e automatização para as redes Meraki. Os casos de uso comuns são:
Provisionamento em massa (usando a API do painel)
Monitoramento avançado (usando MV Sense e APIs MR)
Automação de rede (usando chamadas MS)
Integrações na nuvem (integrar Meraki com dispositivos de terceiros — com Cisco Umbrella, por exemplo)
Cisco Sandbox
O ambiente Cisco DevNet Sandbox permite que engenheiros, desenvolvedores, administradores de rede, arquitetos ou qualquer pessoa que queira desenvolver e testar as APIs, controladores, equipamentos de rede, suíte de colaboração e muito mais da ferramentas da Cisco, possa fazê-lo gratuitamente!
Nesse post faremos um laboratório utilizando a infraestrutura Meraki (Meraki Always On).
Faça login, no dashboard com as credenciais fornecidas, acesse o ambiente “DevNet Sandbox”
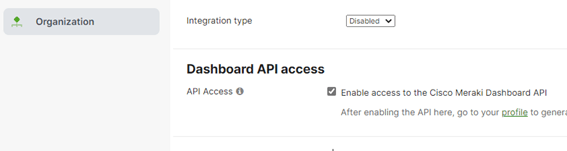
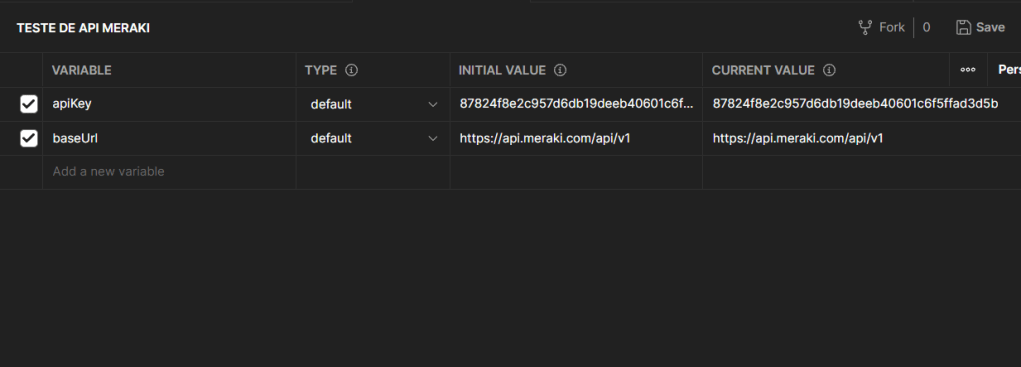
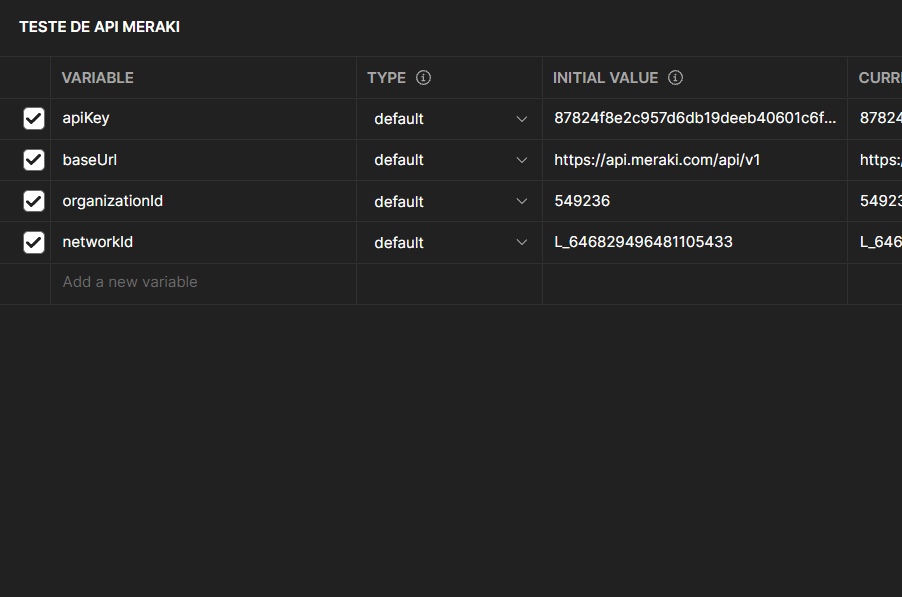
Certifique se o use o uso de API está ativo “Enable access to the Cisco Meraki Dashboard”. Logado no painel vá para: Organization -> Settings -> Dashboard API Access, marque a caixa:
Gere uma API key para aquela conta. Cada conta poderá ter até 2 API Keys.
Clique no seu Perfil (canto superior direito): My Profile -> API Access -> Clique em “Generate API Key” copie e armazene em local seguro.
Postman
Depois de seguir os passos acima, você pode começar a fazer chamadas de API para seu dashboard e dispositivos usando o Postman ou seus scripts Python.
Vamos fazer nossa primeira chamada de API e definir o escopo da nossa documentação da API, pois existem algumas maneiras de fazer isso:
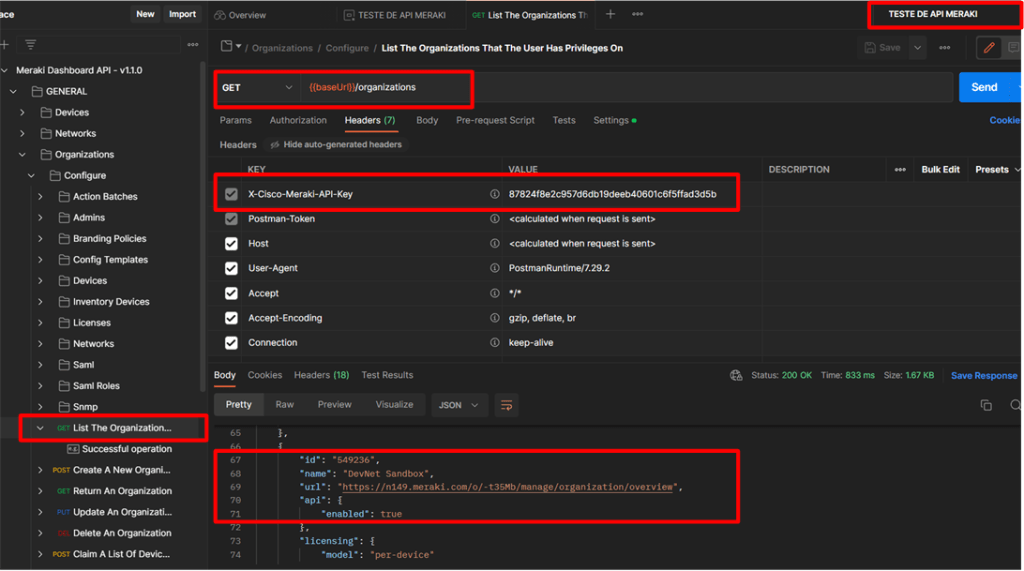
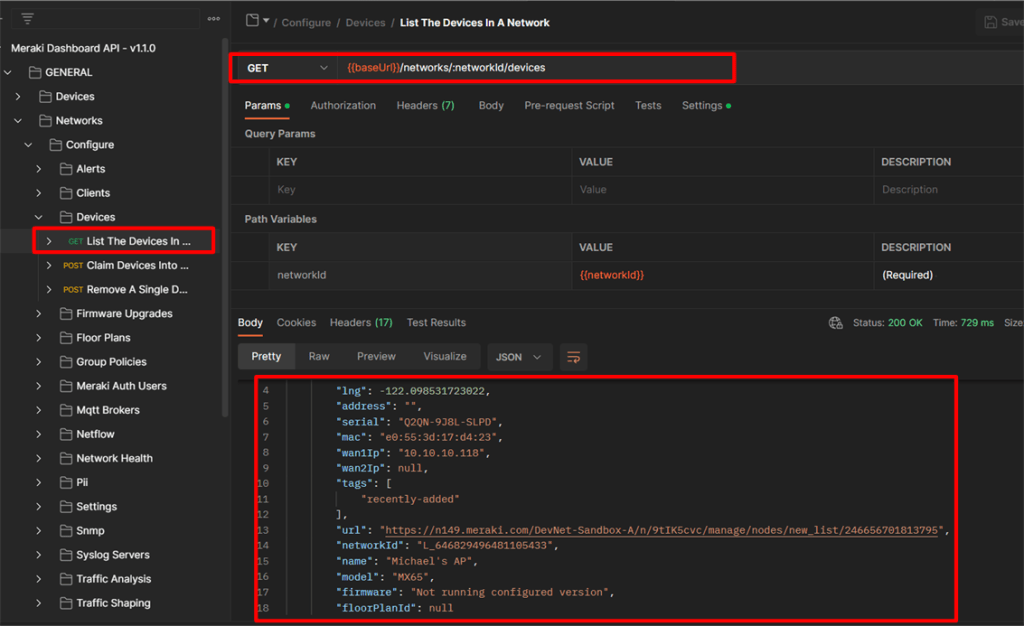
Você pode acessá-lo através do Meraki Dashboard: Clique em Help -> API Docs.
Importe o documento de API mais recente do Postman para sua conta do Postman.
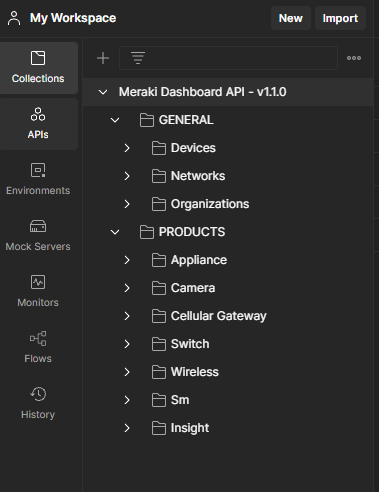
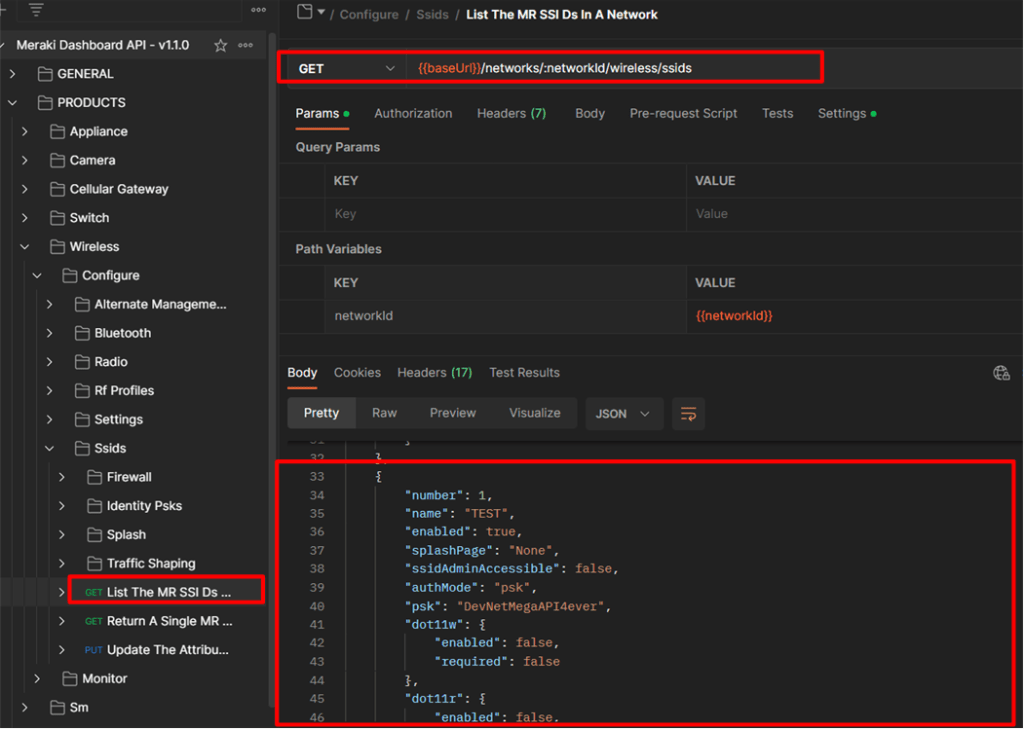
Após importar para sua conta você poderá ver quantas chamadas de API estão disponíveis e como ela está organizada, confira abaixo:
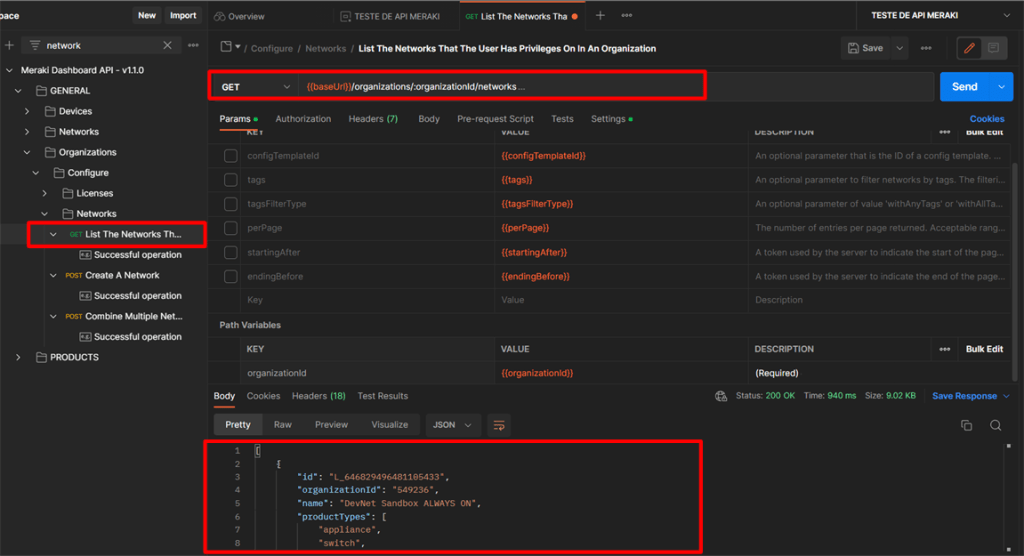
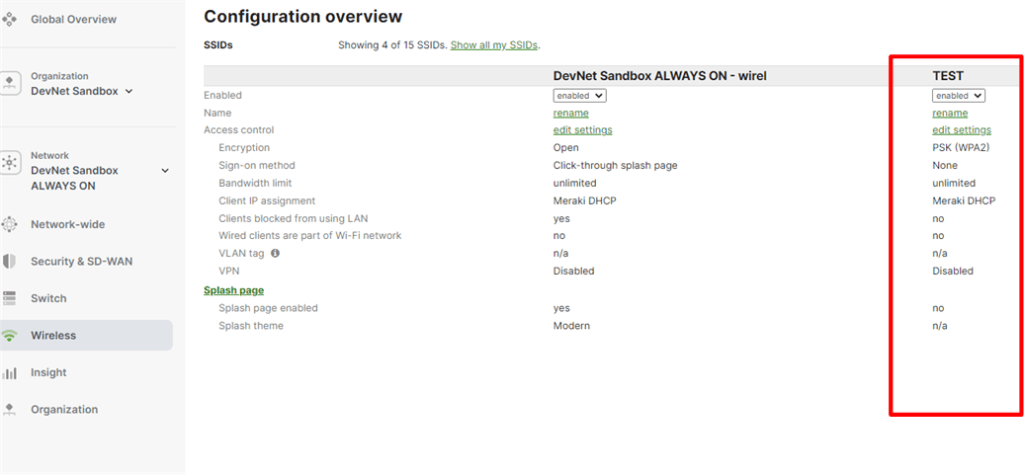
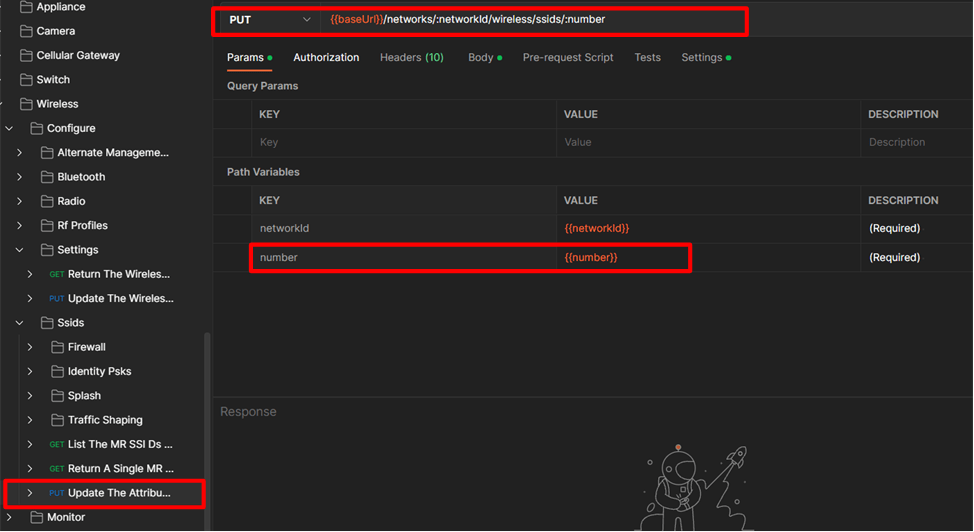
Escolha um request que você possa preencher facilmente com as informações que já possui (por enquanto só temos a chave da API, portanto precisamos de uma solicitação que exija apenas o valor da Chave da API), por exemplo, poderíamos listar todas as Organizações disponíveis no Chave de API que estamos usando, depois de inserir os campos obrigatórios no cabeçalho da API:
Apesar de existirem inúmeros sites em português com ótimas referencias de Introdução ao Protocolo MPLS, escreveremos uma serie de artigos com a utilização de MPLS em diversos cenários. Esse post servirá como uma pequena introdução para a descrição e utilização do protocolo com o foco um pouco mais simples na arquitetura e serviços.
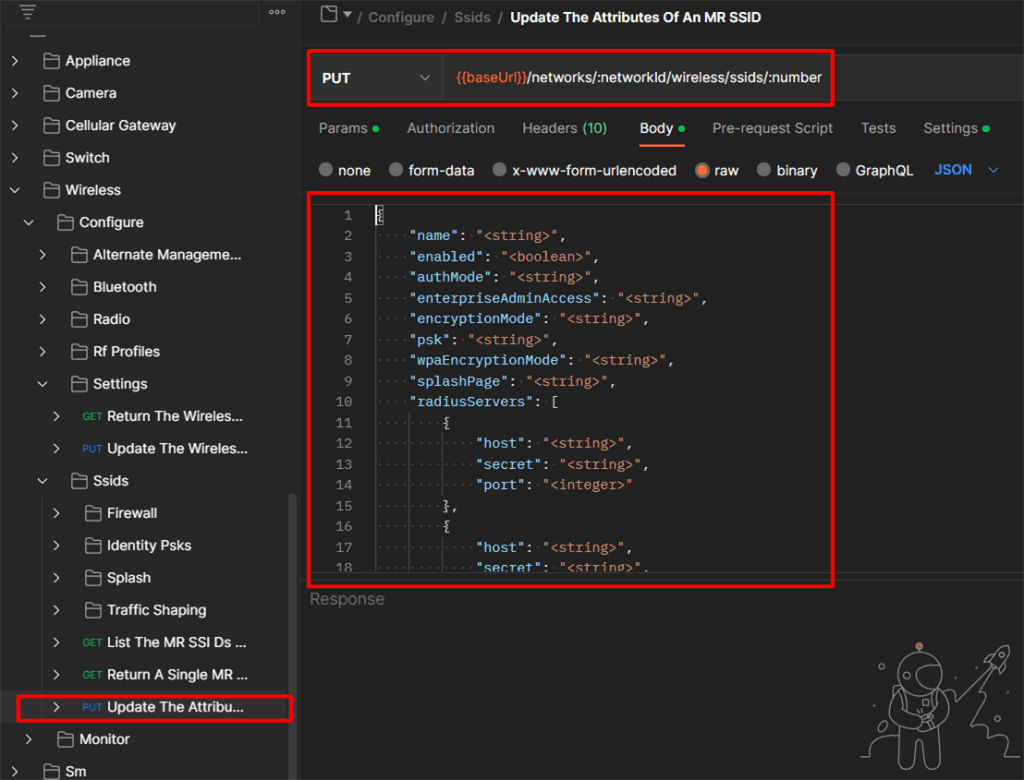
O protocolo MPLS (Multi Protocol Label Switching) foi criado para permitir o encapsulamento de diversos protocolos de rede para serem encaminhados por Roteadores baseando-se apenas no endereço do Label ao invés do endereço de rede. A tecnologia é largamente utilizada pelos Provedores de Internet com diversas topologias de serviços orientado a redes em apenas uma única rede convergida com o MPLS em seu Backbone, permitindo a utilização de Redes Privadas (VPNs MPLS), Qualidade de Serviço (QoS), Any Transport over MPLS (AToM) e Engenharia de tráfego (MPLS-TE).
Ele é chamado de Multiprotocolo pois é utilizado com qualquer protocolo da camada de Rede e em certos cenários permite até o transporte de protocolos da Camada de Enlace sobre MPLS, apesar de quase todo o foco estar voltado no uso do MPLS com o IP.
O objetivo de uma rede MPLS dentro dos Provedores de Serviço não é o de conectar diretamente a sistemas finais. Ao invés disto ela é uma rede de trânsito, para transporte de pacotes.
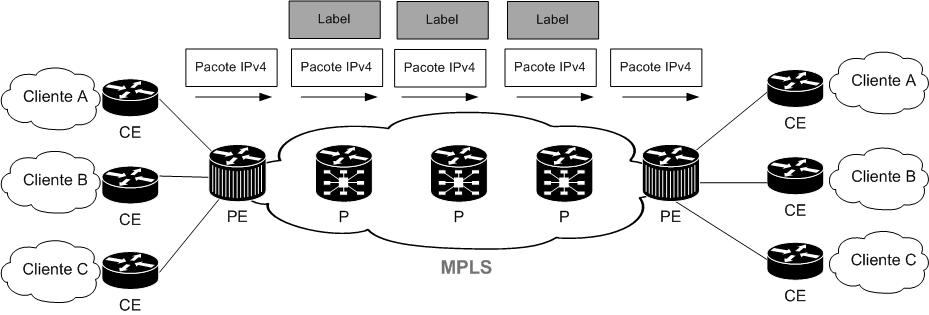
Em sua função básica os Roteadores do Backbone chamados de Provider Routers (P) encaminham o tráfego baseando-se apenas nos Labels. Já os roteadores que são responsáveis por receber os pacotes IP e encapsulá-los com labels em uma rede MPLS são chamados de Provider EdgeRouters (PE).
A terminologia dada aos equipamentos em uma rede MPLS é muito importante para identificarmos a função de cada equipamento na topologia e a sua função na arquitetura.
De certa forma, um cliente ao comprar uma comunicação entre as filiais utilizando um link MPLS privado (MPLS VPN), não terá necessariamente em seus roteadores o encaminhamento de pacotes via labels e muito menos a troca deles. Os roteadores designados para clientes, chamados de Customer Edge Routers (CE) possuem a função de prover conectividade na rede MPLS situados na “borda do cliente” (saída para rede).
A conectividade entre PE e CE poderá ser tanto provida por roteamento estático ou via IGP.
Mas o que são os Labels?
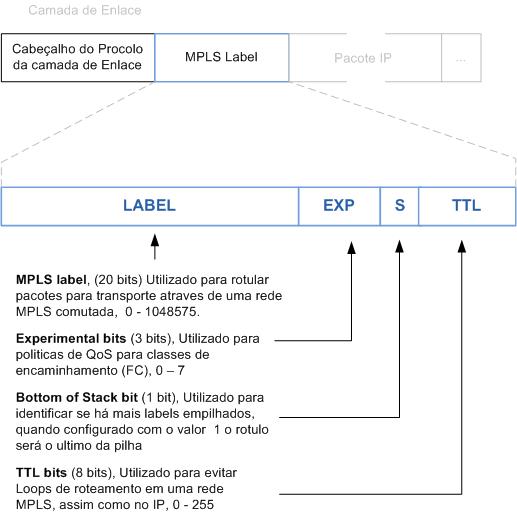
Em uma tradução literal, poderíamos dizer que label teria a atribuição de um rótulo. Em sua função no modo frame o label é inserido na frente do cabeçalho da camada de rede. Um pacote pode ter um ou mais rótulos dependendo do serviço oferecido na rede MPLS.
O label é um identificador, de tamanho fixo e significado local. Todo pacote ao entrar numa rede MPLS recebe um label. Desta forma os roteadores só analisam os labels para encaminhar os pacotes. O cabeçalho MPLS deve ser posicionado depois de qualquer cabeçalho da camada de enlace e antes do cabeçalho da camada de rede, ele é conhecido como Shim Header pelo seu posicionamento entre os 2 cabeçalhos e é “carinhosamente” chamado de protocolo da camada 2,5.do Modelo OSI.
Nos próximos posts daremos foco no processo de encaminhamento e troca de labels, outros termos comuns em uma rede MPLS e a configuração de Roteadores para a troca de labels.
Um grande abraço
Referências:
http://www.gta.ufrj.br/grad/01_2/mpls/mpls.htm http://pt.wikipedia.org/wiki/MPLS Designing and Implementing, IP/MPLS-Based Ethernet Layer 2 VPN Services, An Advanced Guide for VPLS and VLL, Zhuo ( Frank) Xu – Wiley Publishing, INC – 2010 MPLS Fundamentals, Luc De Ghein. – Cisco Press – 2006 TCP sobre MPLS, ENNE, ANTONIO JOSE FIGUEIREDO – Ciência Moderna – 2009
Todos os Roteadores de uma área OSPF possuem a visão completa dos links daquela área e a partir dessa visão calculam individualmente qual o melhor caminho para determinado destino.
Para a formação da tabela dos links, chamado de LSDB, o OSPF baseia-se nos LSA’s (Link State Advertisements) para transmitir informações para os Roteadores Vizinhos. Os principais tipos de LSA’s são:
Tipo 1 – Representa um Roteador Tipo 2 – Representa o DR Tipo 3 – Representam os links de outra Area OSPF declarados por um ABR Tipo 4 – Representa um ASBR (Autonomous System Border Router) Tipo 5 – Representa uma rota externa ao domínio OSPF Tipo 7 – Usado em áreas NSSA.
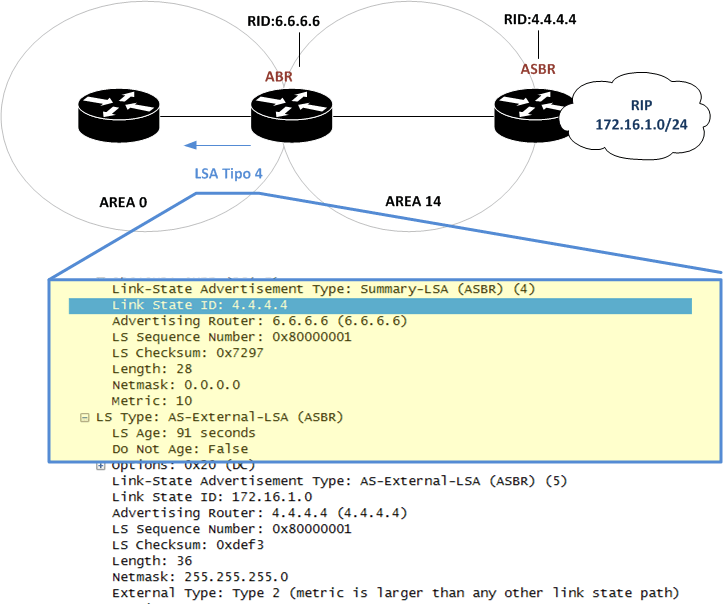
OSPF – LSA Tipo 4 (Summary LSA – ASBR)
Os LSA’s do tipo 4 são gerados pelos Roteadores ABR (Area Border Router), informando o Router ID e o custo para o Roteador ASBR fora da área.
Os Roteadores ASBR são responsáveis por redistribuir destinos externos dentro do processo OSPF, como por exemplo, RIP, Rotas estáticas, interfaces diretamente conectadas não inseridas no OSPF e etc.
LS Age: Tempo em segundos que o LSA foi originado.
Options: Identifica capacidades opcionais suportadas pelo Roteador como circuitos por demanda e etc.
LS Type: Representa o tipo do LSA, neste post citaremos o tipo 4
Link-State ID: Representa o ID do ASBR.
Advertising Router: identifica o Router ID do Roteador que está gerando o LSA.
LS Sequence Number: Identifica os novos LSAs pelo numero de seqüência. Incrementando sequencialmente entre 0x80000001 e 0x7FFFFFFF.
LS Checksum: Verifica o checksum no LSA
Length: Identifica o tamanho do LSA.
Network Mask: No caso do ASBR o valor da mascara será 0.0.0.0
metric: Métrica para o destino
TOS e TOS metric: Representam o tipo de Serviço e geralmente são marcados com o valor 0
Referências
TCP/IP, Volume I 2nd Edition (Jeff Doyle, Jennifer Carroll)
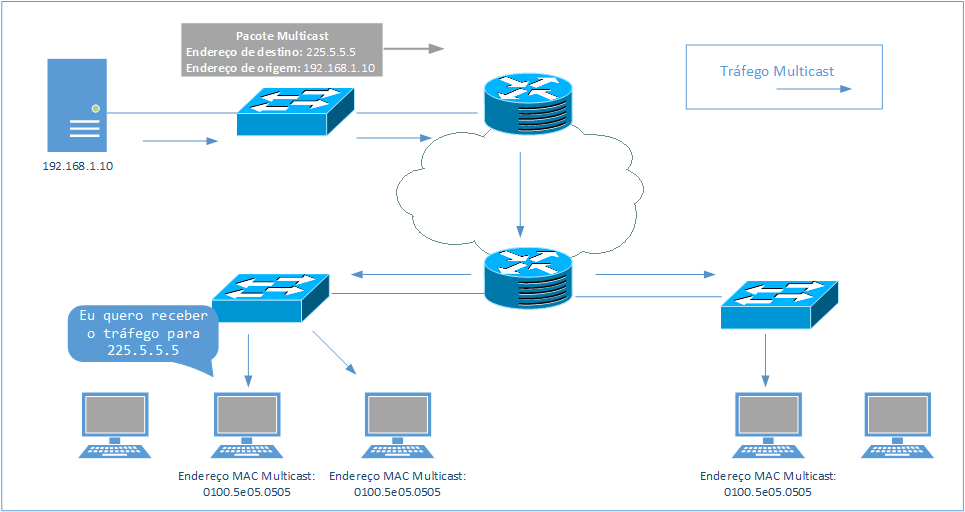
As aplicações multicast utilizam endereços IP multicast que são referenciados como grupos multicast. Diferente de endereços IP unicast, que são atribuídos geralmente para um host, um endereço multicast é utilizado como endereço de destino de um pacote IP. O pacote com endereço IP multicast é transportado pela rede para aplicações especificamente multicast.
Diferente de um endereço unicast, um endereço multicast não é atribuído para um dispositivo de rede. Um endereço de origem no cabeçalho IP de um pacote com destino multicast, deverá ser sempre um endereço unicast.
Endereços IPv4 reservados para uso Multicast
Os endereços IPv4 reservados pela IANA para multicast são classificados como classe D, do range 224.0.0.0 à 239.255.255.255. Não há a necessidade de configurarmos a máscara de rede para endereços multicast pois ele não são hierárquicos. Os primeiros bits do primeiro octeto iniciarão sempre com 1110, os últimos 28 bits não são estruturados.
Diferente de endereços IPv4 unicast onde os blocos são delegados para os Regional Internet Registries (RIRs), os endereços IPv4 multicast são atribuídos pelo IANA. O registro atual de grupos é especificado da seguinte forma:
Sobre a lista acima, o bloco 224.0.0.0/24 é atribuído aos protocolos de roteamento para comunicação local no segmento, como por exemplo 224.0.0.5 que é utilizado pelo OSPF para encaminhar mensagens para todos os roteadores. O bloco 224.0.1.0/24 é utilizado por protocolos de roteamento, mas que podem ser encaminhados por toda a rede privada, como por exemplo o 224.0.1.39 para RP do PIM-SM. O 239.0.0.0/8 possui função similar aos endereços IPv4 da RFC 1918 (endereços IPv4 de escopo privado).
Endereço MAC
A atribuição de um endereço IPv4 multicast para um grupo multicast automaticamente gera um endereço MAC multicast. O endereço MAC reservado inicia com 0100.5e e o restante é completado com os últimos 23 bits do endereço IPv4.
Por exemplo, o endereço 239.1.1.1 gerará o endereço MAC 0100.5e01.0101.
Infelizmente esse método não prove endereços MAC multicast únicos para cada grupo multicast, pois somente os últimos 23 bits são utilizados. O endereço 238.1.1.1 também produz o endereço MAC 0100.5e01.0101, mas a chance de conflito de grupos multicast é muito baixa e caso o conflito aconteça a aplicação validará o endereço IPv4 multicast e descartará o tráfego. Mas o administrador deverá atentar-se a esses cenários ao criar novos grupos multicast.
Referências
CCIE Routing and Switching Certification Guide, 4th Edition, Cisco Press, Wendell Odom, Rus Healy, Denise Donohue
A feature DHCP Snooping permite a proteção da rede contra Servidores DHCP não autorizados.
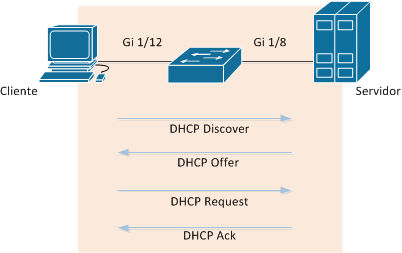
Com o DHCP Snooping configurado, o Switch inspeciona as mensagens DHCP entre uma máquina cliente e servidor com a troca das mensagens: DHCP Discover, DHCP Offer, DHCP Request e o DHCP Ack, como o desenho abaixo:
O comando “ip dhcp snooping” configurado globalmente habilita o serviço no Switch.
Com o serviço habilitado, informe explicitamente qual VLAN deverá filtrar as mensagens DHCP Offer e DHCP Ack ; com o comando “ip dhcp snooping vlanvlan-range”.
ip dhcp snooping
! Habilitando o processo globalmenteip dhcp snooping vlan 20
! Habilitando o dhcp snooping na vlan 20
Os comandos listados restringirão todas as portas do Switch na VLAN 20 como untrusted (não confiável). Filtrando todas as mensagens de oferta do serviço DHCP (a solicitação de serviço DHCP pela máquina cliente não sofrerá nenhuma restrição).
Para o funcionamento do “Servidor DHCP válido” deveremos configurar a porta do Servidor como trusted (confiável) , incluíndo as portas de UpLink. No Exemplo, configuraremos o dhcp-snooping no Switch com a porta GigabitEthernet 1/8 conectada ao servidor DHCP válido como trust.
Configuração
Switch#conf t
Switch(config)#interface GigabitEthernet1/8
Switch(config-if)#ip dhcp snooping trust
Visualisando
O DHCP-Snooping constrói uma tabela que contém o endereço IP liberado pelo servidor DHCP vinculado ao endereço MAC.
Switch# show ip dhcp snooping binding
MacAddress IpAddress Lease(sec) Type VLAN Interface
00:FF:16:89:E6:88 192.168.20.2 86250 dhcp-snooping 10 Gi1/12
Switch# show ip dhcp snooping
Switch DHCP snooping is enabled
DHCP snooping is configured on following VLANs:
20
DHCP snooping is configured on the following Interfaces:
Insertion of option 82 is enabled
circuit-id format: vlan-mod-port
remote-id format: MAC
Option 82 on untrusted port is not allowed
Verification of hwaddr field is enabled
Interface Trusted Rate limit (pps)
------------------------ ------- ----------------
GigabitEthernet 1/8 yes unlimited
GigabitEthernet 1/12 no unlimited
Iremos demonstrar o quão poderá ser vulnerável a sua rede caso você tenha uma community SNMP RFC 1157(RO, RW) habilitada e conhecida pelo agente de ameaça que poderá explorá-la.
Iremos abordar os comandos snmpwalk, snmpget e snmpset, todos fazem parte do pacote open source netsmp, e funciona principalmente em ambiente Linux / Unix / MacOs, também existem ferramentas similares que funcionam em Windows.
Basicamente você poderá fazer uma varredura em todas as OIDs dos dispositivos (Switches, Roteadores, firewalls, Servidores entre outros dispositivos que trabalham com SNMP).
Colocando a mão na massa,e utilizando um MAC OS vamos levantar informações sobre um determinado equipamento e posteriormente iremos alterar um parâmetro de configuração deste equipamento.
Informações Necessárias: Comandos: snmpget / snmpwalk / snmpset Communities:rdefaultro (e apenas de leitura) rdefaultrw (community de leitura e escrita). IP Alvo: 192.168.1.1 Outras Info: Parâmetros de coleta
! Alterando o Campo Contato do Router sh-3.2# snmpset -c 'rdefaultrw' -v 1 192.168.1.1 system.sysContact.0 s teste@rdefault.com.br SNMPv2-MIB::sysContact.0 = STRING: teste@rdefault.com.br sh-3.2# snmpwalk -c 'rdefaultro' 192.168.1.1 system.sysContact.0 SNMPv2-MIB::sysContact.0 = STRING: teste@rdefault.com.br
Melhorando a segurança de equipamentos Cisco que possuem SNMP habilitado:
✓ Utilizar snmpv3 de preferencia com criptografia; ✓ Utilizar ACL restringindo quais IPs poderão realizar consultas snmp; ✓ Não utilizar o nome de comunidade como “public”, pois é um erro comum por se tratar de uma comunidade default; ✓ Habilitar Comunidades Read Write apenas se necessário (Evitando manipulações de MIBs via snmpset):
Conclusão
Nós desejamos você tenham em mente o conceito de “think out of the box”, desta forma os conceitos apresentados neste artigo podem ser implementados na maioria dos equipamentos disponíveis no mercado, mudando apenas a sintaxe de implementação e ou ferramenta utilizada. Para este artigo foi utilizando um router Cisco com IOS.
O ambiente Cisco DevNet Sandbox permite que engenheiros, desenvolvedores, administradores de rede, arquitetos ou qualquer pessoa que queira desenvolver e testar as APIs, controladores, equipamentos de rede, suíte de colaboração e muito mais da ferramentas da Cisco, possa fazê-lo gratuitamente!
Os ataques ao protocolo STP geralmente têm como objetivo assumir a identidade do switch root da rede, ocasionando assim cenários de indisponibilidade na rede. Programas como o Yersinia permitem gerar esse tipo de ataque. Há também cenários em que usuários adicionam switches não gerenciados e hubs (propositadamente ou não) com o intuito de fornecer mais pontos de rede em ambientes que deveriam ser controlados.
As funcionalidades comentadas no vídeo usam como referência Switches 3Com/HP para mitigar os ataques ao STP, mas servem como exemplo para todos principais vendors. As features são: Root Protection (Root Guard), BPDU Protection (BPDU guard) com STP edged-port (portfast) e loop protection (loop guard).